pandas数据处理,字符串先拆分再合并
目录
概述
实现之前文章中用SQL实现的功能:
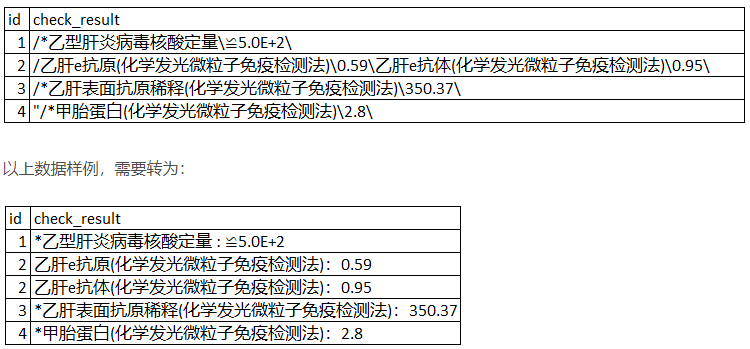
得益于python简洁的表达式,以及pandas库的强大功能,实现起来非常轻松,关键代码仅三行:
代码
读取数据,预处理
import pandas as pd
# load data
df_org = pd.read_csv(r'D:\check_data.csv',sep='|',usecols=['结果'], encoding= 'utf-8')
df = df_org.copy()
# add index to column
df = df.reset_index()
# rename and drop none value
df.rename(columns={'index':'id','结果':'result'},inplace=True)
df.dropna(inplace=True)
原始样本数据
# org data where id in (2,3,32)
df[df['id'].isin([2,3,32])]
| id | result | |
|---|---|---|
| 2 | 2 | /*乙型肝炎病毒核酸定量\8.05E+6\ |
| 3 | 3 | /*甲胎蛋白(化学发光微粒子免疫检测法)\1.4\ |
| 32 | 32 | /乙肝e抗原(化学发光微粒子免疫检测法)\88.15\乙肝e抗体(化学发光微粒子免疫检测法)... |
关键代码
# strip and split to list
df['result'] = df['result'].str.strip('/\\').str.split('\\')
# to key:value format
df['result'] = df['result'].apply(lambda x:[f'{k}:{v}' for k, v in zip(x[0::2],x[1::2])])
# list value to rows
df = df.explode('result').reset_index(drop=True)
结果样本数据
# see result where id in (2,3,32)
df[df['id'].isin([2,3,32])]
| id | result | |
|---|---|---|
| 51 | 2 | *乙型肝炎病毒核酸定量:8.05E+6 |
| 52 | 3 | *甲胎蛋白(化学发光微粒子免疫检测法):1.4 |
| 279 | 32 | 乙肝e抗原(化学发光微粒子免疫检测法):88.15 |
| 280 | 32 | 乙肝e抗体(化学发光微粒子免疫检测法):11.42 |
说明
- 第一步,将字符拆分拆分为列表,用series.str.split实现
- 第二步,每两个值进行合并,用zip函数结合列表推导式批量实现
- 第三步,将不固定长度的 list 形式的列数据,转为行,用pandas的explode函数实现