概述
用Python实现之前文章中用SQL实现的转换,交叉表转为长宽表。
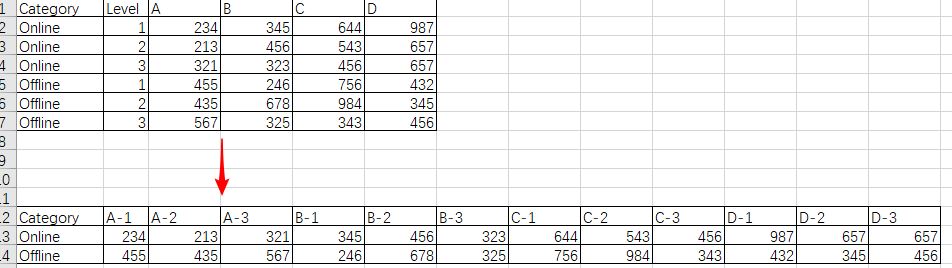
数据准备
import pandas as pd
df = pd.read_csv(r'D:\CategoryConfig.csv')
|
Category |
Level |
A |
B |
C |
D |
| 0 |
Online |
1 |
234 |
345 |
644 |
987 |
| 1 |
Online |
2 |
213 |
456 |
543 |
657 |
| 2 |
Online |
3 |
321 |
323 |
456 |
657 |
| 3 |
Offline |
1 |
455 |
246 |
756 |
432 |
| 4 |
Offline |
2 |
435 |
678 |
984 |
345 |
| 5 |
Offline |
3 |
567 |
325 |
343 |
456 |
方法一,先列转行(UnPivot),拼接后再行转列(Pivot)
# melt方法列转行,然后拼接新列
df_melt = df.melt(id_vars = ['Category','Level'],value_vars=['A','B','C','D'],var_name='Type')
df_melt['xType'] = df_melt['Type'] + '-' + df_melt['Level'].astype(str)
|
Category |
Level |
Type |
value |
xType |
| 0 |
Online |
1 |
A |
234 |
A-1 |
| 1 |
Online |
2 |
A |
213 |
A-2 |
| 2 |
Online |
3 |
A |
321 |
A-3 |
| 3 |
Offline |
1 |
A |
455 |
A-1 |
| 4 |
Offline |
2 |
A |
435 |
A-2 |
# 数据透视
df_result = pd.pivot_table(df_melt[['Category','xType','value']],
index='Category',
columns='xType',
values = 'value',
aggfunc='max')
df_result.reset_index(inplace=True)
| xType |
Category |
A-1 |
A-2 |
A-3 |
B-1 |
B-2 |
B-3 |
C-1 |
C-2 |
C-3 |
D-1 |
D-2 |
D-3 |
| 0 |
Offline |
455 |
435 |
567 |
246 |
678 |
325 |
756 |
984 |
343 |
432 |
345 |
456 |
| 1 |
Online |
234 |
213 |
321 |
345 |
456 |
323 |
644 |
543 |
456 |
987 |
657 |
657 |
方法二,先透视,再重命名列名
df_result = pd.pivot_table(df,index='Category',columns='Level')
|
A |
B |
C |
D |
| Level |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
| Category |
|
|
|
|
|
|
|
|
|
|
|
|
| Offline |
455 |
435 |
567 |
246 |
678 |
325 |
756 |
984 |
343 |
432 |
345 |
456 |
| Online |
234 |
213 |
321 |
345 |
456 |
323 |
644 |
543 |
456 |
987 |
657 |
657 |
如上所示,列名为双层索引结构,下一步将其压平为一层结构
df_result.columns = ['-'.join(map(str,c)) for c in df_result.columns]
df_result.reset_index(inplace=True)
|
Category |
A-1 |
A-2 |
A-3 |
B-1 |
B-2 |
B-3 |
C-1 |
C-2 |
C-3 |
D-1 |
D-2 |
D-3 |
| 0 |
Offline |
455 |
435 |
567 |
246 |
678 |
325 |
756 |
984 |
343 |
432 |
345 |
456 |
| 1 |
Online |
234 |
213 |
321 |
345 |
456 |
323 |
644 |
543 |
456 |
987 |
657 |
657 |